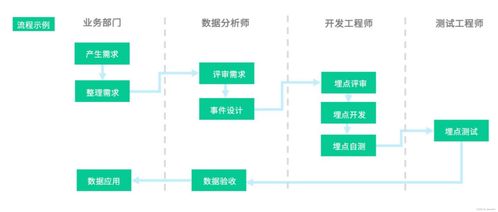
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的決策環(huán)境中,埋點(diǎn)數(shù)據(jù)是理解用戶行為、優(yōu)化產(chǎn)品體驗(yàn)的基石。從用戶的一次點(diǎn)擊、一次瀏覽到一次購(gòu)買,這些看似微小的行為都被精心設(shè)計(jì)的埋點(diǎn)捕獲,轉(zhuǎn)化為原始數(shù)據(jù)流。原始數(shù)據(jù)本身并無價(jià)值,只有經(jīng)過系統(tǒng)化、專業(yè)化的數(shù)據(jù)處理,才能提煉出驅(qū)動(dòng)業(yè)務(wù)增長(zhǎng)的洞察。本文將探討埋點(diǎn)數(shù)據(jù)的處理流程、核心挑戰(zhàn)與最佳實(shí)踐。
數(shù)據(jù)處理始于埋點(diǎn)方案的嚴(yán)謹(jǐn)設(shè)計(jì)。一個(gè)清晰的埋點(diǎn)規(guī)范是后續(xù)所有工作的前提,它需要明確定義每個(gè)事件(Event)的名稱、屬性(Properties)以及觸發(fā)時(shí)機(jī)。例如,“加入購(gòu)物車”事件應(yīng)包含商品ID、價(jià)格、數(shù)量等屬性。混亂的埋點(diǎn)設(shè)計(jì)會(huì)導(dǎo)致數(shù)據(jù)“臟亂差”,使后續(xù)清洗成本激增。因此,數(shù)據(jù)團(tuán)隊(duì)需要與產(chǎn)品、研發(fā)部門緊密協(xié)作,確保埋點(diǎn)采集的準(zhǔn)確性與一致性。
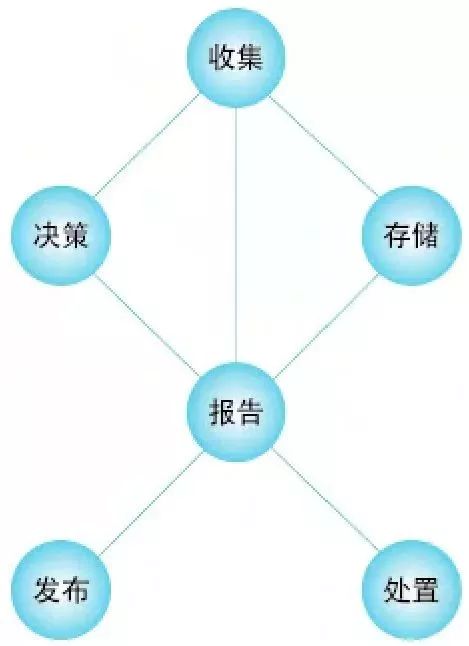
當(dāng)海量埋點(diǎn)數(shù)據(jù)涌入數(shù)據(jù)管道,數(shù)據(jù)處理的核心階段便隨之展開。這一過程通常包含幾個(gè)關(guān)鍵步驟:
- 數(shù)據(jù)采集與傳輸:數(shù)據(jù)通過SDK從客戶端(Web、App等)或服務(wù)器發(fā)出,經(jīng)由日志收集系統(tǒng)(如Apache Kafka)實(shí)時(shí)或批量傳輸?shù)綌?shù)據(jù)倉(cāng)庫(kù)(如Hadoop HDFS、云存儲(chǔ)等)。確保傳輸?shù)姆€(wěn)定、低延遲與不丟失是此環(huán)節(jié)的重中之重。
- 數(shù)據(jù)清洗與解析:原始日志通常是半結(jié)構(gòu)化或非結(jié)構(gòu)化的JSON字符串。此步驟需要將其解析、展開,并清洗掉無效數(shù)據(jù)(如空值、測(cè)試數(shù)據(jù)、格式錯(cuò)誤的數(shù)據(jù))。例如,過濾掉內(nèi)部員工的訪問日志,矯正異常的時(shí)間戳。
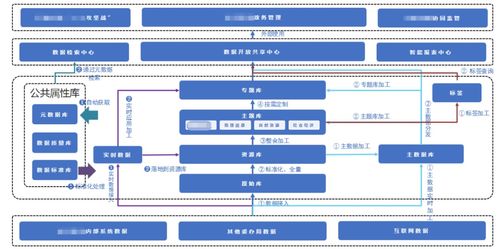
- 數(shù)據(jù)建模與整合:清洗后的數(shù)據(jù)被按照主題(如用戶、商品、流量)組織成易于理解的數(shù)據(jù)模型(如星型模型、維度建模)。這一步將分散的埋點(diǎn)事件與業(yè)務(wù)數(shù)據(jù)庫(kù)中的用戶信息、商品信息等進(jìn)行關(guān)聯(lián)整合,形成完整的用戶行為旅程視圖。
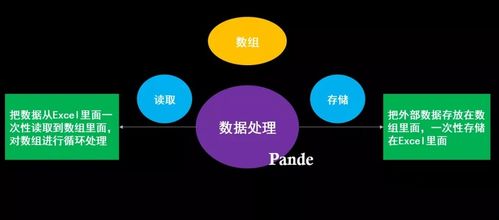
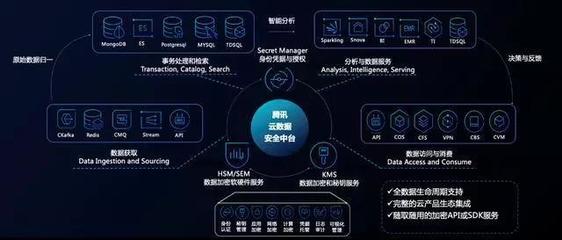
- 數(shù)據(jù)存儲(chǔ)與計(jì)算:處理后的數(shù)據(jù)存入適合分析的數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)湖(如Snowflake, BigQuery, ClickHouse)。在此之上,通過SQL或大數(shù)據(jù)計(jì)算引擎(如Spark, Flink)進(jìn)行聚合計(jì)算,生成每日活躍用戶(DAU)、轉(zhuǎn)化漏斗、用戶留存率等關(guān)鍵指標(biāo)。
- 數(shù)據(jù)可視化與洞察:數(shù)據(jù)通過BI工具(如Tableau, Looker, 國(guó)內(nèi)如FineBI)以報(bào)表或儀表盤的形式呈現(xiàn)給業(yè)務(wù)人員。分析師可以基于此進(jìn)行深度挖掘,回答諸如“新改版功能是否提升了轉(zhuǎn)化?”等業(yè)務(wù)問題。
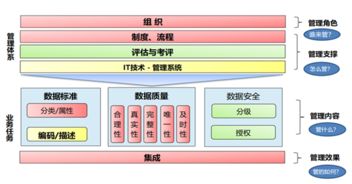
在整個(gè)流程中,數(shù)據(jù)質(zhì)量監(jiān)控與數(shù)據(jù)治理是貫穿始終的生命線。需要建立自動(dòng)化的數(shù)據(jù)質(zhì)量校驗(yàn)規(guī)則,監(jiān)控?cái)?shù)據(jù)量的異常波動(dòng)、字段取值的分布是否合理,并及時(shí)告警。建立統(tǒng)一的數(shù)據(jù)字典和指標(biāo)口徑,避免“數(shù)據(jù)孤島”和指標(biāo)歧義。
面對(duì)日益復(fù)雜的業(yè)務(wù)場(chǎng)景和嚴(yán)格的隱私法規(guī)(如GDPR、個(gè)人信息保護(hù)法),數(shù)據(jù)處理也面臨著巨大挑戰(zhàn)。如何在數(shù)據(jù)采集階段做好匿名化與脫敏,如何在數(shù)據(jù)處理流程中確保安全合規(guī),成為技術(shù)與管理并重的課題。
埋點(diǎn)數(shù)據(jù)的處理絕非簡(jiǎn)單的技術(shù)堆砌,而是一個(gè)將原始行為“礦石”冶煉成決策“黃金”的系統(tǒng)工程。它要求技術(shù)上的嚴(yán)謹(jǐn)可靠,更要求對(duì)業(yè)務(wù)的深刻理解。只有構(gòu)建起高效、穩(wěn)健、可信的數(shù)據(jù)處理流水線,埋點(diǎn)所蘊(yùn)含的巨大價(jià)值才能真正釋放,成為企業(yè)智能化運(yùn)營(yíng)的核心引擎。