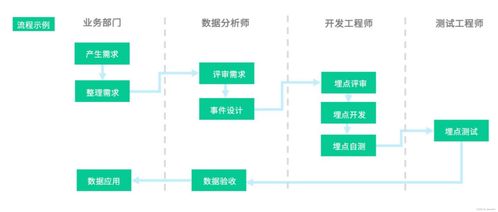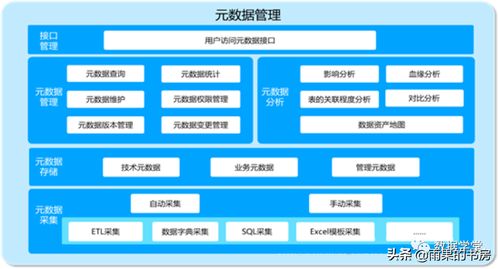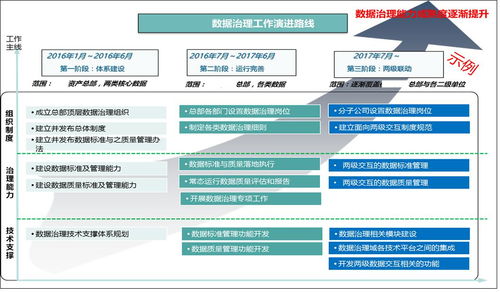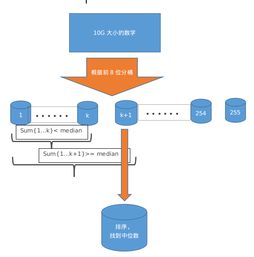
隨著大數據時代的到來,海量數據處理已成為現代計算機科學的核心挑戰之一。在數據處理流程中,排序作為基礎操作,其效率和可擴展性直接決定了整個系統的性能。傳統排序算法如快速排序、歸并排序在處理GB級數據時表現優異,但在TB甚至PB級別的數據面前,我們需要重新思考排序技術的設計與實現。
一、傳統排序算法的局限性
傳統排序算法主要針對內存中的數據設計,假設所有數據可以一次性加載到內存中進行操作。然而在海量數據場景下,這種假設不再成立。數據量可能遠超單機內存容量,導致頻繁的磁盤I/O操作,使得時間復雜度為O(n log n)的算法在實際運行中效率急劇下降。
二、外部排序技術的革新
外部排序成為處理海量數據的關鍵技術。多路歸并排序通過將數據分成多個塊,分別排序后再合并,有效減少了磁盤I/O次數。基于SSD的新型外部排序算法進一步提升了性能,利用SSD的隨機讀寫特性優化了數據訪問模式。
三、分布式排序架構
面對超大規模數據,分布式排序成為必然選擇。MapReduce框架中的Shuffle階段本質上就是一個分布式排序過程。新一代數據處理系統如Apache Spark通過內存計算和彈性分布式數據集(RDD)優化了排序性能,特別是在迭代計算場景下表現出色。
四、近似排序與采樣技術
在某些應用場景中,精確排序并非必需。近似排序算法通過采樣和統計方法,以可接受的誤差換取性能的大幅提升。特別是對于數據探索和可視化等場景,基于抽樣的快速排序能夠提供足夠準確的結果。
五、硬件加速與專用處理器
GPU和FPGA等專用硬件為排序算法帶來了新的可能。利用GPU的并行計算能力,可以實現數量級的性能提升。一些研究顯示,在特定數據分布下,GPU加速的排序算法比CPU實現快10倍以上。
六、未來發展趨勢
隨著量子計算和神經形態計算的發展,排序算法可能迎來根本性變革。量子排序算法理論上可以在O(√n)時間內完成排序,雖然目前仍處于理論研究階段,但代表著未來的發展方向。
海量數據處理的排序技術正在經歷從單機到分布式、從精確到近似、從通用計算到專用硬件的多元化發展。在實際應用中,我們需要根據數據特征、硬件環境和業務需求,選擇合適的排序策略,才能在效率與準確性之間找到最佳平衡點。